HashMap和红黑树B树B+树 |
您所在的位置:网站首页 › 江淮 蔚来 › HashMap和红黑树B树B+树 |
HashMap和红黑树B树B+树
|
HashMap
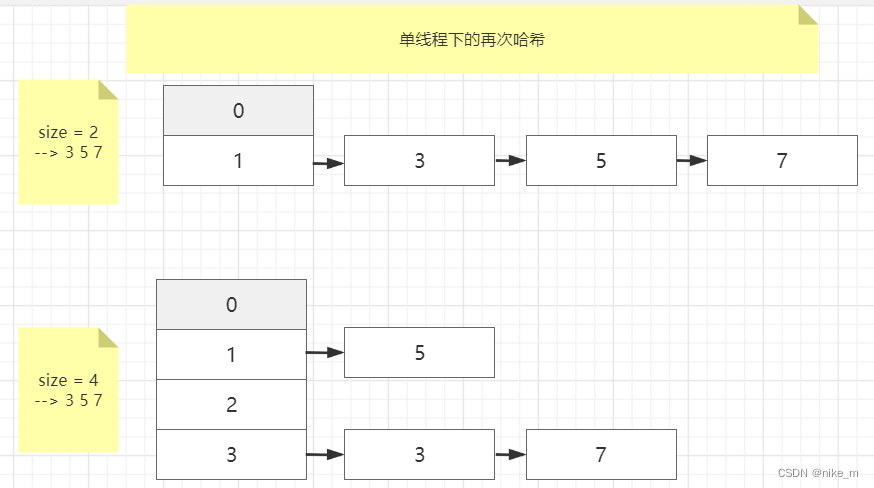
Hash算法和hash表hash冲突解决Hash冲突的方法有四种HashMapJDK1.8后, HashMap优化HashMap底层实现原理HashMap扩容机制为什么选取红黑树而不是B树或者B+树?HashMap不安全HashMap 线程安全实现
Hash算法和hash表
hash算法就是将任意长度的输入经过hash(key)的算法变成固定长度的输出,输出的结果就是一个散列值 hash表就是散列表,就是通过key直接访问到内存存储位置的数据结构,就是hash(key) 得到一个address,通过这个地址获取数据,从而加快数据的查找。 hash冲突hash冲突就是由于hash算法,被计算的数据是无限多,可能性未知的,但是要把这些存放到一个固定范围内,总会存在不同的数据,得到相同的值,这就是hash冲突。 解决Hash冲突的方法有四种 开放地址法(线性探测法)确定hash冲突的地址,从这个地址出发,按照次序从hash表中找到一个空闲位置,将这个冲突的元素存放在这个位置。 TheadLocal类解决hash冲突的方法 链式寻址法这个就是遇到hash冲突之后,将数据连接到冲突元素之后,拉出一个链表,链表存放冲突的元素 HashMap类解决hash冲突的方法 再次hash当遇到hash冲突的时候,选择再次hash,直到hash出的地址没有冲突,但是这样在时间上会有消耗,最坏情况下,每次的再次hash出的地址都是冲突的。 建立公共溢出区建立两个表,分为基本表和溢出表,当发生hash冲突的时候,将数据加入到溢出表中 HashMap源码 node 默认大小 16 static final int DEFAULT_INITIAL_CAPACITY = 16;HashMap 内部存储结构 静态内部类 Node implements 了 Map 接口内部的 Entry 接口 HashMap.Node next; Node(int hash, K key, V value, HashMap.Node next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }在JDK1.8之后,java对HashMap做了改进,当链表的长度大于8的时候,后面的数据存储在红黑树中,以便加快检索的速度 负载因子:默认值为0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f;元素的总个数 大于 当前数组的长度 * 负载因子。数组会进行扩容,扩容为原来的两倍 链表长度大于 8 的时候 会转化成为红黑树,当红黑树的深度小于 6 时,红黑树会自动退化成为链表 红黑树 本质上是一个二叉查找树,在二叉查找树基础上,增加了着色和相关的性质使红黑树相对平衡,从而保证了,query,insert,delete的时间复杂度最坏为O(log n), 加快检索速率。 static final class TreeNode extends java.util.LinkedHashMap.Entry { HashMap.TreeNode parent; HashMap.TreeNode left; HashMap.TreeNode right; HashMap.TreeNode prev; boolean red; } JDK1.8后, HashMap优化优化1 jdk1.7 HashMap 数据结构 = 数组 + 单向链表 JDK7 的hashmap是基于数组+链表实现的,在底层维护了一个Entry数组,根据计算的hashcode的值,将对应的kv存储到该数组中,一旦发生hash冲突,就会将KV键值对放到对应的元素的后面,此时便形成了一个链表的数据结构类型。 缺点:在不断的发生hash冲突的时候,在桶上的链表会越拉越长,查询的效率就会越来越低。时间复杂度为O(n) jdk1.8,HashMap 数据结构 = 数组 + 单向链表 + 红黑树 JDK8的hashmap是基于数组+单向链表+红黑树实现的,它的底层维护了一个Node数组。当链表的元素个数大于 8的时候,链表会自动转化为红黑树,,这样做可以保证在冲突很大的前提下,查询效率的高效,链表的查询时间复杂度是O(n),红黑树时间复杂度是O(logN) 优化2 红黑树,链表插入节点的方式,jdk1.7中,头插法,jdk1.8之后,尾插法。 优化3 jdk1.8的hash()中,将hash值高位(前16位)参与到取模的运算中,使得计算结果的不确定性增强,降低发生哈希碰撞的概率。 优化4 扩容优化,jdk1.7扩容对所有的数据进行hash, 但是jdk1.8中,通过高位 & 运算 检查高位来判断元素是否需要移动(0:不移动 1 : 移动) 移动的计算方式:新的下表位置 = 原下标位置 + 原数组长度 HashMap底层实现原理HashMa是基于hash算法的通过put或者get方式获取对象 存储对象的时候,我们传入K/V给put方法,put方法调用hashcode计算hash从而得到桶的位置,进一步存储。这时候,hashmap会根据桶的容量自动调节容量,超过Load Factor则resize为原来的2倍。 获取对象的时候,我们将key传入给get方法,它会调用hashcode计算出hash从而得到桶的位置,进一步调用equals方法进行比较 HashMap扩容机制 数组的初始化容量设置为16,容量是以2的次方进行扩容的。目的提高性能使用足够大的数组,位运算代替取模运算数组是否需要扩容是根据扩容因子决定的。默认0.75,可以自己根据构造器传入进行修改,但是不建议,大量实验证明0.75最合理。为了解决碰撞,数组的元素是以单向链表进行存储的,当链表到达一个阈值(7|8)的时候,链表会自动转化为红黑树提高性能。当链表的长度缩小为6 的时候,红黑树退化成为链表。链表在转为红黑树之前,会先检测数组是否到达阈值,如果没有到达这个容量,放弃转化,先去扩容数组。 为什么选取红黑树而不是B树或者B+树?平衡二叉树【Balanced Binary Tree or Height-Balanced Tree】 AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差的绝对值不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。Windows NT内核中广泛存在红黑树 一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。 每个节点非红即黑根节点是黑的;每个叶节点都是黑的;如果一个节点是红的,那么它的两儿子都是黑的;对于任意节点而言,其到叶子点每条路径都包含相同数目的黑节点;每条路径都包含相同的黑节点; 应用1.C++ 的STL中,地图和集都是红黑树做的 2.Linux的进程调度完全公平的调度程序用的是红黑树管理的PCB,进程的虚拟内存区域都存储在一颗红黑树上,每一个虚拟的内存区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间 3.IO多路复用的epoll实现采取的是红黑树管理的sockfd,以便支持更快的CRUD 4.Nginx中红黑树管理计时器,因为红黑树有序,很快就可以获取到最短距离 5.JAVA中的TreeMap就是基于红黑树实现的 B树 B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。特征根节点至少有两个子节点 每个中间节点都包含k-1个元素和k个孩子,其中 m/2 ≤ k ≤ m (m为树的阶) 每个叶子节点都包含k-1个元素,其中 m/2 ≤ k ≤ m (m为树的阶) 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分(一个结点有k个孩子时,必有k-1个元素才能将子树中所有元素划分为k个子集) B+树 B+树是B树的一种变形体有K个子节点的节点必然有K个关键码非叶节点仅具有索引作用,元素信息均存放在叶节点中树的所有叶节点构成一个有序链表,可以按照关键码排序的次序遍历全部记录B+树内部节点不包含数据信息,内存中可以存放更多的key,数据更加的紧密,空间局部性更好,因此访问叶子上相关联的数据具有很好的缓存命中率。叶子节点相邻,遍历树只需要线性遍历叶子节点即可,由于数据顺序排列并且相连,所以便于区间查找和搜索,而B树需要每一层进行递归遍历,相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。二叉查找树时间复杂度是O(logN),效率已经很高了,但是大量的数据最初都是先存储在磁盘上的,在执行查询操作的时候,需要从磁盘中读取数据到内存中(IO),而且不能一次性全部读入到内存中,只能逐一加载一个磁盘页【也就是树的一个节点】,磁盘IO很慢,由于二叉查找树的深度过大,IO次数多导致效率低下,就得降低树的深度,于是就出现了B树和B+树,一个节点存储多个元素,多叉树的结构,大大降低了树的深度,提高了效率,数据库的底层就采用的B+ 树B/B+树多用于外存中,对磁盘很友好的数据结构。 HashMap本身就是数组+链表,由于链表查询慢的情况所以采取查询效率高的树型数据结构来代替。如果采取B/B+树的话,在数据量不是很多的情况下,数据都会挤在同一个节点中,这时候遍历的效率就变成了链表 HashMap不安全1、如果多个线程同时使用put方法添加元素,而且假设正好存在两个put的key发生了碰撞(hash值一样),那么根据HashMap的实现,这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程的put的数据被覆盖。 2、如果多个线程同时检测到元素个数超过数组大小 * loadFactor,这样就会发生多个线程同时对Node数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给table,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失。 《java并发编程的艺术》: HashMap在并发执行put操作时会引起死循环,导致CPU利用率接近100%。因为多线程会导致HashMap的Node链表形成环形数据结构,一旦形成环形数据结构,Node的next节点永远不为空,就会在获取Node时产生死循环。 HashMap通常会用一个指针数组(table[]),来做分散所有的key,当加入元素时,hash算法通过key计算出这个数组的下标 i,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。 HashMap 在单线程情况下是安全的,在多线程下是不安全的。 Hashtable线程安全,但效率低,因为是Hashtable是使用synchronized的,所有线程竞争同一把锁;而ConcurrentHashMap不仅线程安全而且效率高,因为它包含一个segment数组,将数据分段存储,给每一段数据配一把锁,也就是所谓的锁分段技术。 安全实现: // Hashtable Map hashtable = new Hashtable(); // synchronizedMap Map synchronizedHashMap = Collections.synchronizedMap(new HashMap()); // ConcurrentHashMap jdk 1.5 Map concurrentHashMap = new ConcurrentHashMap(); |
 多线程下:在扩容中使用头插法,将旧数组中的值插入到新数组中,出现死循环。头插法会将链表逆序。
多线程下:在扩容中使用头插法,将旧数组中的值插入到新数组中,出现死循环。头插法会将链表逆序。【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |